Esta es una traducción del texto original escribo por Hammer-Eran Lahav.













Valet clave para la Web por Hammer-Eran Lahav
Muchos coches de lujo cuentan con una llave de valet. Es una llave especial que da el encargado del aparcamiento y, a diferencia de su clave de regular, sólo permitirá el coche para ser conducido a una corta distancia al tiempo que bloquea el acceso al maletero y el teléfono móvil a bordo. A pesar de las restricciones de la clave de valet impone, la idea es muy inteligente. Darle a alguien el acceso limitado a su coche con una llave especial, mientras con la otra llave para desbloquear todo lo demás.
A medida que la web crece, más y más sitios dependen de los servicios distribuidos y computación en la nube: un laboratorio de impresión fotográfica de su fotos de Flickr, una red social utilizando la libreta de direcciones de Google para buscar amigos, o una aplicación de terceros que utilizan las API de servicios múltiples.
El problema es, a fin de que estas aplicaciones para acceder a los datos del usuario en otros sitios, piden usuarios y contraseñas. Esto no sólo requiere la exposición de las contraseñas de usuario a otra persona - a menudo la misma contraseña utilizada para la banca en línea y otros sitios - sino que también proporciona acceso a estas aplicaciones ilimitadas para hacer lo que quieran. Pueden hacer cualquier cosa, incluyendo el cambio de las contraseñas y el bloqueo de los usuarios.
OAuth proporciona un método para que los usuarios de conceder el acceso de terceros a sus recursos sin tener que compartir sus contraseñas. También proporciona una forma de conceder el acceso limitado (en el alcance, duración, etc.)
Por ejemplo, un usuario de la web (propietarios de los recursos) puede otorgar un servicio de impresión (cliente) el acceso a sus fotos privada almacenada en un servicio para compartir fotos (servidor), sin compartir su nombre de usuario y contraseña con el servicio de impresión. En su lugar, se autentica directamente con el servicio para compartir fotos que emite el servicio de impresión de la delegación específica de credenciales.
Más allá de cliente-servidor
En el modelo de autenticación de cliente-servidor, el cliente utiliza sus credenciales para acceder a los recursos alojados en el servidor. OAuth introduce una tercera función de este modelo: el propietario del recurso. En el modelo de OAuth, el cliente (que no es el propietario del recurso, sino que actúa en su nombre) las solicitudes de acceso a los recursos controlados por el propietario del recurso, sino alojado en el servidor.
Para que el cliente para acceder a los recursos, primero tiene que obtener el permiso del propietario del recurso. Este permiso se expresa en la forma de un token y juego secreto compartido. El propósito de la muestra es hacer innecesario que el propietario del recurso a compartir sus credenciales con el cliente. A diferencia de las credenciales de los recursos dueño, el token se pueden emitir con un alcance restringido y limitada de por vida, y revocar de forma independiente.
Tomando la inspiración de la comunidad de microformatos, la comunidad OAuth ha tomado una decisión en base a la primera versión del protocolo sobre las prácticas bien establecidas. OAuth representa la sabiduría combinada de muchos protocolos de la industria de propiedad, como Google AuthSub, Yahoo BBAuth, Twitter OAuth y Flickr API.
Cada protocolo ofrece un método distinto para el intercambio de credenciales de usuario para un token. OAuth fue creado por el estudio cuidadoso de cada uno de estos protocolos, la participación de sus autores, y extraer las mejores prácticas y comunes para apoyar a las nuevas implementaciones, así como una transición gradual de los servicios existentes para apoyar OAuth.
Un área donde OAuth es más evolucionado que algunos de los protocolos y servicios es la manipulación directa de los servicios no web. OAuth tiene soporte integrado para aplicaciones de escritorio, dispositivos móviles, set-top boxes, y de los sitios web del curso.
Historia.
OAuth Core 1.0
La comunidad OAuth, en gran medida, surgió de la comunidad OpenID. Alrededor de noviembre de 2006 Blaine Cook (http://romeda.org/) fue el encargado de añadir soporte OpenID para Twitter, donde se desempeñó como arquitecto en jefe. Blaine también estaba buscando un método de autenticación más para la API de Twitter, que no requiriera que los usuarios de Twitter pudieran compartir sus nombres de usuario y contraseñas con las aplicaciones de terceros.
Al mismo tiempo, Chris Messina (http://factoryjoe.com/) estaba trabajando junto a Larry Halff (http://larryhalff.com/) y el equipo de Ma.gnolia en la integración de OpenID en el panel de Widgets de Ma.gnolia (el servicio Ma.gnolia se suspendió en febrero de 2009). Blaine y Chris se pusieron en contacto en diciembre de 2006 y organizaron una reunión con David Recordon (http://www.davidrecordon.com/) (OpenID co-creador) y otros en el Citizen Space OpenID para discutir las soluciones existentes.
Después de revisar la funcionalidad existente de OpenID y las limitaciones de su diseño, así como los protocolos de propietario, el grupo llegó a la conclusión de que había una necesidad de un nuevo estándar abierto para el control de acceso a la API que no requieren compartir la contraseña de inicio de sesión, lo que permite tecnologías como OpenID para su uso con llamadas a la API. Llamaron a la nueva iniciativa OpenAuth (inspirado en OpenID).
En abril de 2007, el OpenAuth Google Group (http://groups.google.com/group/openauth) fue creado con un pequeño grupo de ingenieros que trabajan en conjunto para producir una propuesta de un protocolo abierto. Resultó que este problema no es exclusivo de OpenID, con los desarrolladores de aplicaciones. El grupo original incluía Blaine Cook, Kellen Elliott-McCrea (http://laughingmeme.org/), Larry Halff, Hunt Tara (http://www.horsepigcow.com/), McKeller Ian (http://ian.mckellar.org/), Chris Messina, y unos cuantos más.
El 16 de abril de 2007, AOL presentó su protocolo OpenAuth (http://dev.aol.com/api/openauth). El protocolo de AOL se centró en el uso del sistema de acceso de AOL para autenticar a los usuarios de otras aplicaciones (por ejemplo, para entrar en el servicio AIM mediante una aplicación de terceros). Esto obligó al grupo a buscar un nuevo nombre, y el 5 de mayo de 2007, el nombre fue elegido OAuth (pronunciado oh-auth).
A principios de junio de 2007, DeWitt Clinton (http://blog.unto.net/) de Google se enteró del proyecto y expresó su interés en apoyar el esfuerzo. DeWitt llevó el esfuerzo de la atención del equipo de seguridad de Google y fueron Ben Laurie (http://www.links.org/) y Jonathan Sergent involucrados.
El 10 de junio de 2007, Blaine Cook y Kellen Elliott-McCrea, escribió el primer esbozo.
El 14 de junio, David Recordon se unió al esfuerzo de redacción. También se reunió con George Fletcher (http://practicalid.blogspot.com/) y Praveen Alavilli (http://whyidentity.blogspot.com/) de AOL para discutir la propuesta.
El grupo se reunió de nuevo a finales de junio de 2007 en FooCamp (http://wiki.oreillynet.com/foocamp07/index.cgi). En julio de 2007 después de la primera iPhoneDevCamp (http://www.iphonedevcamp.org/), que contó con la asistencia y el OAuth fué discutido por primera vez en público, se decidió que había llegado el momento de abrirlo a otros a unirse.
El público OAuth Google Group (http://groups.google.com/group/oauth) fue creado el 10 de julio y el 15 de julio David Recordon lleva a la colección de notas y lo convirtió en el proyecto las especificaciones reales (http://groups.google.com/group/openauth/web/spec?version=4).
Maquetas iniclaes del Logo OAuth por Chris Messina
A medida que el grupo se abrió durante FooCamp y iPhoneDevCamp, y se movieron a la nueva lista otros colaboradores como Mark Atwood (http://mark.atwood.name/), John Panzer (http://www.johnpanzer.com/), Sandler Eran (http://eran.sandler.co.il/), y Slesinsky Brian (http://slesinsky.org/brian/). El 26 de julio el proyecto por primera vez se publicó (http://groups.google.com/group/openauth/web/spec). El 5 de agosto de 2007, Michal Migurski (http://mike.teczno.com/) presentó la primera Implementacion Cliente de OAuth en PHP y Python, diseñado para trabajar con el entonces privado prototipo de Twitter OAuth API.
El 27 de julio de 2007, Hammer-Eran Lahav (http://hueniverse.com/) se unió al proyecto y empezó a contribuir a la especificación, con el tiempo adquirió un puesto en la comunidad como editor. El 21 de agosto y el 28, el grupo se reunió en persona en la oficina de Twitter, y trabajaron juntos para elaborar un proyecto 0.9 (http://code.google.com/p/oauth/source/browse/spec/trunk/oauth.html?spec=svn33&r=33).
Entre julio y noviembre de 2007, la comunidad publicó siete proyectos adicionales. Los proyectos recibieron un interés creciente, retroalimentación de la comunidad y las contribuciones, sobre todo la limpieza a las especificaciones iniciales de Larry Halff y Sieling Todd (http://www.toddsieling.com/Todd_Sieling.html), y la reestructuración del documento y la transición hacia el "flujo unificado" (un flujo de trabajo único para las tres clases de clientes - en la web de escritorio basado, y móvil) de Eran martillo Lahav.
El 4 de diciembre, la especificación Core OAuth 1.0 (http://oauth.net/core/1.0/) fue declarada como finalizada en el “Internet Identity Workshop” (http://www.internetidentityworkshop.com/), superando a OpenID 2.0 por un día. Ma.gnolia tuvo la primera implementación en vivo OAuth producción. El 26 de agosto de 2008, después de la ayuda de Gabe Wachob (http://blog.wachob.com/) y el equipo legal de Yahoo!, todos los colaboradores originales de la especificación de OAuth y su empleador ejecutó el OAuth y el acuerdo de licencia (http://hueniverse.com/2008/08/oauth-licensed-a-step-on-the-way-to-the-open-web/), lo que garantiza que la especificación seguirá siendo libre y disponible para todos los ejecutores.
Terminología
Cliente, Servidor y Propietario de Recurso.
OAuth define tres roles: el cliente, el servidor y el propietario del recurso (llamado el Triángulo de Amor OAuth por Leah Culver). Estos tres roles están presentes en cualquier transacción OAuth, en algunos casos, el cliente también es el propietario del recurso. La versión original de la especificación utiliza un conjunto diferente de condiciones de estos roles: consumidor (cliente), proveedor de servicios (servidor), y el usuario (propietario del recurso).
En el modelo de autenticación de cliente-servidor, el cliente utiliza sus credenciales para acceder a los recursos alojados en el servidor. A lo que el servidor concierne, el secreto compartido utilizado por el cliente pertenece al cliente. El servidor no le importa de dónde viene o si es el cliente actúa en nombre de alguna otra entidad.

Hay muchas veces cuando el cliente está actuando en nombre de otra entidad. Esa entidad puede ser otra máquina o persona. Cuando un tercer actor está involucrado, por lo general un usuario interactuar con el cliente, el cliente está actuando en nombre del usuario. En estos casos, el cliente no accede a sus recursos propios, sino los del usuario - el propietario del recurso.
En lugar de utilizar las credenciales del cliente, el cliente está utilizando las credenciales del propietario de los recursos para hacer las solicitudes - que pretende ser el propietario del recurso. Las credenciales de usuario suelen incluir un nombre de usuario o la pantalla de nombre y una contraseña, pero los propietarios de los recursos no se limitan a los usuarios, que pueden ser de cualquier entidad que controla los recursos del servidor.

El modelo se hace un poco más detallado cuando el cliente es una aplicación basada en web. En ese caso, el cliente se divide entre un componente de front-end, por lo general se ejecutan en un navegador web en el escritorio del propietario del recurso, y un componente de fondo, que se ejecutan en el servidor del cliente.
El propietario de los recursos está interactuando con una parte de la aplicación cliente mientras el servidor está recibiendo peticiones de otra parte.
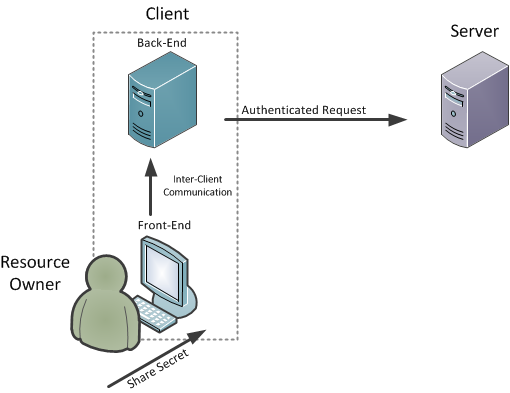
Recursos Protegidos
Un recurso protegido es un recurso almacenado en (o prestados por) el servidor que requiere autenticación para acceder a él. Los recursos protegidos son propiedad o están controlados por el propietario del recurso. Cualquier persona que solicite el acceso a un recurso protegido debe estar autorizado para ello por el propietario del recurso (impuesta por el servidor).
Un recurso protegido puede ser de datos (fotos, documentos, contactos), servicios (colocar el punto del blog, la transferencia de fondos), o cualquier otro recurso que requieren restricciones de acceso. Mientras OAuth puede ser utilizado con otros protocolos, este solo está definido para recursos HTTP(S).
2 piernas, 3-piernas, n-piernas
El número de piernas se utiliza para describir una solicitud de OAuth, normalmente se refiere al número de partes involucradas. En el flujo de OAuth simple: un cliente, un servidor, y un propietario de los recursos, el flujo se describe como tres piernas. Cuando el cliente es el propietario del recurso (es decir, actuando en nombre propio), se describe como dos piernas. Piernas adicionales por lo general significan diferentes cosas para diferentes personas, pero en general significa que el acceso es compartido por el cliente con otros clientes (re-delegación).
Credenciales y Tokens
OAuth utiliza tres tipos de credenciales: las credenciales del cliente, las credenciales temporales, y las credenciales de testigo. La versión original de la especificación utiliza un conjunto diferente de los términos de estas credenciales: clave del consumidor y clave secreta (las credenciales del cliente), solicitud de token y la clave secreta (credenciales temporales), y el token de acceso y clave secreta (credenciales token). La especificación sigue utilizando un nombre de parámetro 'oauth_consumer_key "por razones de compatibilidad.
Las credenciales del cliente se utiliza para autenticar al cliente. Esto permite al servidor recopilar información sobre los clientes que utilizan sus servicios, ofrecen a algunos clientes un trato especial, tales como límite de acceso libre, o proporcionar el propietario del recurso, con más información sobre los clientes que quieran acceder a los recursos protegidos. En algunos casos, las credenciales del cliente no se puede confiar y que sólo puede ser utilizado sólo para fines informativos, como en los clientes de aplicaciones de escritorio.
Las credenciales Token se utilizan en lugar del nombre de usuario del propietario del recurso y la contraseña. En lugar de que el propietario del recurso comparta sus credenciales con el cliente, este autoriza al servidor para emitir una clase especial de credenciales para el cliente que representa la concesión de acceso proporcionada al cliente por el propietario del recurso. El cliente utiliza las credenciales de token de acceso al recurso protegido sin tener que saber la contraseña del propietario del recurso.
Las credenciales Token incluyen un identificador de señal, por lo general (pero no siempre) una cadena aleatoria de letras y números que es único, difícil de adivinar, y se combina con un Token Secret para proteger la señal de ser utilizados por personas no autorizadas. Las credenciales Token son generalmente limitados en su alcance y duración, y puede ser revocado en cualquier momento por el propietario del recurso sin afectar a otras credenciales token emitidas a otros clientes.
El proceso de autorización OAuth también utiliza un conjunto de credenciales temporales que se utilizan para identificar la solicitud de autorización. Con el fin de dar cabida a diferentes tipos de clientes (basado en la web, de escritorio, móviles, etc), las credenciales temporales ofrecen una mayor flexibilidad y seguridad.
En OAuth 1.0, el medio secreto de cada conjunto de credenciales se define como un secreto de simétrica compartida. Esto significa que tanto el cliente y el servidor debe tener acceso a la misma cadena de clave secreta. Sin embargo, OAuth es compatible con un método de autenticación basado en RSA, que utiliza un cliente secreto de asimétrica. Las credenciales diferentes se explican con más detalle más adelante.
Protocolo de flujo de trabajo
OAuth se explica mejor con ejemplos reales. La introducción de la especificación incluye un ejemplo similar pero se centra en la sintaxis de llamadas HTTP. Este recorrido muestra una sesión típica de OAuth, e incluye las perspectivas de los propietarios de los recursos, cliente y servidor. Los sitios web y personas que se mencionan son ficticios. Las referencias de Escocia son reales. Y así comienza nuestra historia ...
Jane está de vuelta de sus vacaciones en Escocia. Pasó dos semanas en la isla de "Islay sampling Scotch". Cuando llega a casa, Jane quiere compartir algunas de sus fotos de vacaciones con sus amigos. Jane utiliza Faji, un sitio para compartir fotos de viaje. Ella firma en su cuenta (se logea) en faji.com, y sube dos fotos que ella marca como privadas.
Utilizando la terminología de OAuth, Jane es el propietario del recurso y Faji el servidor. Las 2 fotos de Jane son los recursos protegidos.

“Después de compartir sus fotos con algunos de sus amigos en línea, Jane quiere también compartir con su abuela. Ella no quiere compartir su botella rara de con nadie. Pero la abuela no tiene una conexión a Internet, Jane planea encargar las impresiones y enviarlas por correo tradicional a la abuela. Siendo una persona responsable, Jane utiliza Beppa, un servicio de impresión fotográfica amigable con el medio ambiente”.
Utilizando la terminología de OAuth, Beppa es el cliente. Habiendo Jane marcado las fotos como privadas, Beppa debe utilizar OAuth para acceder a las fotos para imprimirlas.
“Jane visita beppa.com y comienza a ordenar las impresiones. Beppa permite importar imágenes desde muchos sitios para compartir fotos, incluyendo Faji. Jane selecciona las fotos y da clock a continuar”.

Cuando Beppa.com añadio soporte a la importación de fotos de Faji.com, un desarrollador de Beppa.com que conoce OAuth programó obtiene un conjunto de credenciales para habilitarlas o usadas en las APIs OAuth de Faji.
Desde de que Jane da click en continuar, algunas cosas importantes pasan entre el fondo de Beppa y Faji.
Beppa solicita a Faji el conjunto de credenciales temporales. En este punto, las credenciales temporales no son propietadad del dueño del recurso (es decir, no las conoce el usuario), y puede ser utilizado por Beppa para obtener la aprobación de Jane para acceder a sus fotos privadas.
Jane da clic en Continuar y está esperando en cambio en su pantalla. Ella bebe de su preciado Bowmore Negro a la espera de la siguiente página.
Cuando Beppa recibe las credenciales temporales, esta redirecciona a Jane a "Faji OAuth" con la credenciales temporales y pide a Faji para redirigir a Jane de regreso una vez haya sido aprobada en http://beppa.com/order.
Jane se ha dirigido a Faji y se le pedirá que firme en el sitio (se logee). OAuth requiere que los servidores primero autentiquen al propietario del recurso, y luego pide que permitan el acceso al cliente.
Jane sabe que se encuentra en una página Faji mirando la URL del navegador, y entra en su nombre de usuario y contraseña.

OAuth permite a Jane mantener su nombre de usuario y contraseña como privadas y no compartirlas con Beppa o cualquier otro sitio. En ningún momento Jane entra sus credenciales en beppa.com.
Después de iniciar sesión correctamente en Faji, Jane se le pide que conceda el acceso a Beppa, el cliente. Faji informa a Jane le estan solicitan acceso (en este caso Beppa) y el tipo de acceso. Jane puede aprobar o denegar el acceso.
Jane asegura que Beppa consiga el acceso limitado que necesita. Ella no quiere permitir que Beppa cambie sus fotos o hacer cualquier otra cosa por ella. También se señala que este acceso se hara una sola vez y durante 1 hora que debería ser tiempo suficiente para Beppa a busque sus fotos.

Una vez que Jane aprueba la solicitud, Faji marca las credenciales temporales de recursos autorizados por el propietario Jane. El navegador de Jane es redirigido a Beppa, a la dirección que ya ha proporcionado http://beppa.com/order junto con el identificador de credenciales temporales. Esto permite a Beppa saber que puede continuar para buscar las fotos de Jane.
Jane espera por Beppa para ver sus fotos que estan en su cuenta de Faji.

Mientras Jane espera, Beppa usa el token de solicitud autorizado y lo cambia por un token de acceso. El Request Token es sólo son bueno para obtener la aprobación del usuario, mientras que los Access Token para tener acceso a los recursos protegidos, en este caso las fotos de Jane. En la primera solicitud, intercambia con Beppa el token de solicitud para un token de acceso y en el segundo recibe solicitud de las fotos.
Estando Jane en Beppa, se refresca el navegador para completar el pedido.
Beppa trajo fotos de Jane exitosamente. Se presentan como imágenes en miniatura para su selección.
Jane está muy impresionada de ver cómo Beppa agarró sus fotos sin pedirle su nombre de usuario y contraseña.

